Javaで簡単に文字コードを自動判別するライブラリ!文字化けさせずにファイルインポートでバイト情報に変換する方法!
様々なプログラムを組んでいて外部ファイルのインポートやエクスポートを機能を実装したい時、
ファイルの形式、文字コードなどを考慮した設計にする必要がありますよね。
ファイルの形式はMimeTypeなどを指定してあげれば、
簡単に判定をかけれますが、問題はファイルの文字コードの方です。
プログラミングをしている人なら一度は経験したことがあるのではないでしょうか?
プログラムに読み込ませた外部ファイルが文字化けして、
エラーになってしまったり、うまく動作しなくなってしまったなんてことがありますよね。
特にプログラムの利用者はインポートするファイルの文字コードを意識しないので、
プログラム側で対応していない文字コード情報が直接的な不具合の原因に繋がるかもしれません。
文字コードを意識したコーディングが重要
よくある手法のひとつとして、ファイルのインポート時に、
ユーザーにインポートするファイルの文字コードを選択してもらうというものがあります。
ファイルはプログラム内ではストリーム形式で処理され、
実データはバイト単位の情報を元に、文字コードを識別して文字列として変換します。
この処理の際に必要なのが文字コードの書式であり、
ストリーム形式で取得した情報を文字コードに対応させ、バイト情報として扱いますね。
ですが、プログラマとしてはユーザーに文字コードを意識させることなく、
システムを運用していくような想定で設計・開発していくのが望ましいです。
ならばどうするかと言いますと、入力されたストリーム形式の情報の
文字コードを自動判別してあげて、バイト情報に変換する前に、文字コードを確定してあげる必要があります。
今回はJavaを例に文字コードの自動判別機能を実装するためのサンプルプログラムをご紹介したいと思います。
Javaでインポートされたファイルの文字コードを自動判別する方法
まずは文字コードを自動判別させるクラスをひとつ定義します。
String型で受け取ったファイルパスをそのままストリームでバイト変換する前に利用します。
FileCharDetecter.class
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 | package jp.co.sample; import org.mozilla.universalchardet.UniversalDetector; /** * 文字コードを判定するクラス. * @author Administrator */ public class FileCharDetecter { private String file; // コンストラクタ public FileCharDetecter(String file) { this.file = file; } /** * 文字コードを判定するメソッド. * @param ファイルパス * @return 文字コード */ public String detector() throws java.io.IOException { byte[] buf = new byte[4096]; String fileName = this.file; java.io.FileInputStream fis = new java.io.FileInputStream(fileName); // 文字コード判定ライブラリの実装 UniversalDetector detector = new UniversalDetector(null); // 判定開始 int nread; while ((nread = fis.read(buf)) > 0 && !detector.isDone()) { detector.handleData(buf, 0, nread); } // 判定終了 detector.dataEnd(); // 文字コード判定 String encTyle = detector.getDetectedCharset(); if (encoding != null) { System.out.println("文字コード = " + encType); } else { System.out.println("文字コードを判定できませんでした"); } // 判定の初期化 detector.reset(); return encType; } } |
文字コードを判定させたい処理をコーディングしたクラスに、
上記のFileCharDetecter.classをインポート指定してあげます。
使い方は文字コードを判定させたいファイルのパスをこのクラスに通してあげて、
返ってきた文字コードをストリームのバイト変換時に使用するというものです。
以下は文字コードを判定し、そのままバイト変換するサンプルコードを記載しています。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | // 文字コード判定処理 String filePath = "ファイルパスを指定して下さい"; String line; BufferedReader br; // 変数fdのdetector() : メソッドを実行すると文字コードが判定可能 FileCharDetector fd = new FileCharDetector(filePath); //BufferdReaderで文字列情報を変換 br = new BufferedReader(new InputStreamReader( new FileInputStream( new File(filePath)) ,fd.detector())); // 1行単位で文字列を出力する while( (line=br.readLine())!=null ) System.out.println(line); |
FileInputStreamクラスを利用する際に、ファイルパスと文字コードを指定して、文字列情報を取得させますよね?
例えば、この際に文字コードを固定で“UTF-8”などと指定してしまうと、
UTF-8ではない文字コードのファイルだった場合、確実に文字化けします。
それを回避するために、今回実装したFileCharDetectorクラスが活躍するわけです。
自動でファイル形式を判別し、そのままFileInputStreamクラスで文字コード指定を自動化できるので、文字化けさせずに文字列情報をJavaプログラム内で処理させることができます。
UTF-8のBOMあり形式の文字コードには非対応
様々な文字コードに対応させることはできるのですが、
UTF-8形式でBOM有の設定をしたファイルを利用すると文字化けしてしまう、
もしくは、例外が発生してしまう場合があるかもしれません。
BOM有りのUTF-8とは?
BOMとは簡単に言ってしまえば、ヘッダー情報のことですね。
バイト順マーク(Byte Order Mark)とも呼ばれ、文書ファイルの先頭に付けるバイナリデータのことです。
BOM指定したUTF-8はファイル内の文字列情報の先頭に3バイトのバイナリ情報(EF BB BF)が付加されます。
テキストエディタなどで、UTF-8形式のファイルを保存する時に、
設定項目にUTF-8のBOM有という項目はみたことありますでしょうか?
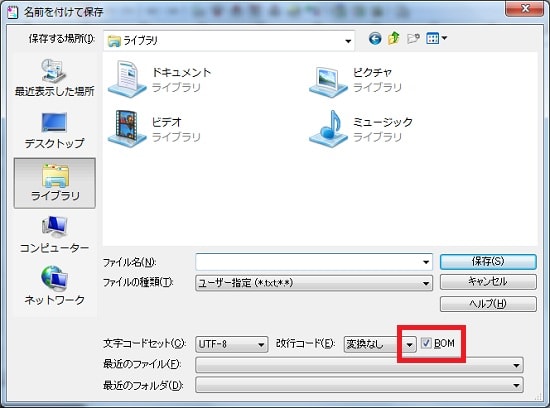
特に意識しなくても、基本はBOM無になっているのですが、何かのタイミングでBOM有にしてしまったり、
他のアプリケーションツールがBOM有のUTF-8形式でファイルを保存する仕組みの場合、非常に厄介です。
BOM指定のUTF-8で文字化けする原因
私もPHP言語のプログラムで外部ファイルを扱うソフトウェアを開発したことがあるのですが、
UTF-8形式で原因不明のエラーに直面し困ったことがありました。
原因はUTF-8にBOMが付加されていたことでした。
そもそも日本語はプログラム側では1文字につき4バイトの構成で出来上がっています。
そこに3バイト分のBOMが先頭に付加されることで、1バイト分ずれてしまいます。
それが要因でたいていのプログラムでBOM形式のテキスト文書で文字化けしてしまいます。
正直なところBOMなんてものは全く持って必要ないです。
プログラムでファイルインポート処理を実装するたびにBOMに悩まされます。
ファイルの文字コード自動判定ソースの注意点
長々とBOMについての文章を書いてしまいましたが、
何が言いたいかと言いますと、今回ご紹介しました文字コード自動判別ソースは
UTF-8のBOM指定を識別できないので、もしかしたら不具合が発生するかもしれません。
テキスト文書のBOM指定そのものを識別する方法がロジック的になさそうなので、
もしBOMを除去するなら、先頭の3バイト分を手動で判別する必要があります。
もしロジック的にBOMを除去する方法があるなら是非知りたいところです。
最新記事 by よっき (全て見る)
- 「圧着」と「圧接」の違い!コネクタを使った効率的な配線作業! - 2019年10月26日
- 夏の暑さ対策は大丈夫?冷却性能抜群のおすすめCPUクーラー!メモリに干渉しない最強の商品を紹介! - 2018年5月1日
- 自作PC弐号機のケースを換装!SilverStone製のミニタワーで冷却性とかっこよさを追求! - 2018年3月11日
スポンサードリンク
こちらの記事もどうぞ!
 ContactForm7の添付ファイルに日本語名を使う方法!WordPressのお問い合わせ画面機能をカスタマイズ!
ContactForm7の添付ファイルに日本語名を使う方法!WordPressのお問い合わせ画面機能をカスタマイズ! TrackLightningの文字化けの原因と対処法!リポジトリブラウザのソース表示時の文字コードの設定!SVNサービスの再起動の手順!
TrackLightningの文字化けの原因と対処法!リポジトリブラウザのソース表示時の文字コードの設定!SVNサービスの再起動の手順! イントラマートでPOSTやJSONを任意のJavaクラスに自動代入!StrutsのActionForm実装でJSPリクエストをサーブレット処理!アノテーション機能の使い方と意味は?
イントラマートでPOSTやJSONを任意のJavaクラスに自動代入!StrutsのActionForm実装でJSPリクエストをサーブレット処理!アノテーション機能の使い方と意味は? JAVAの継承クラスは超簡単?オーバーライドやコンストラクタの仕組みは?インスタンス化してメソッドやメンバ変数へのアクセス方法!
JAVAの継承クラスは超簡単?オーバーライドやコンストラクタの仕組みは?インスタンス化してメソッドやメンバ変数へのアクセス方法! JavaのJdbcManagerでSQL文を楽々作成!Listと組み合わせてクエリ制御する方法!
JavaのJdbcManagerでSQL文を楽々作成!Listと組み合わせてクエリ制御する方法!